
Les grands modèles de langage (LLM) semblent formidables en matière de prédiction, mais souvent, il s’agit simplement d’un travail de mémoire. Cela a des implications pour les investisseurs qui souhaitent utiliser les LLM pour l’analyse économique.
Et si je vous disais que je sais exactement quel était le taux d’inflation en juin 2015, que le S&P 500 a clôturé à 2810 points le 2 mai 2020, et que je sais aussi de manière certaine combien de fois le taux de chômage aux États-Unis a été supérieur à 9 % depuis 1990 ? Vous penseriez alors que je suis un génie économique, soit… que j’ai triché. C’est exactement ce que font les grands modèles de langage comme ChatGPT, et c’est là que le bât blesse.
Dans un récent article universitaire intitulé The Memorization Problem, des chercheurs de l’université de Floride montrent que les LLM (comme GPT-4o) ne se contentent pas de mémoriser des données : ils ont une mémoire quasi encyclopédique des chiffres économiques, des cours de la Bourse et même des titres du Wall Street Journal. Et cette mémoire est parfaite… tant qu’il s’agit du passé.
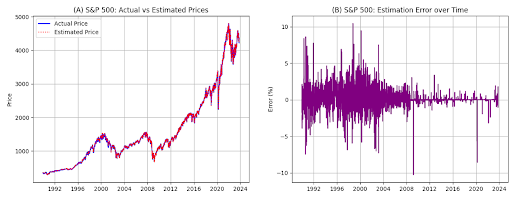
Graphique : Le graphique montre les valeurs du S&P 500 estimées par la LLM par rapport aux valeurs réelles. Le panneau A montre les valeurs réelles par rapport aux valeurs estimées. Le panneau B montre l’erreur d’estimation, calculée comme (Estimé – Réel) / Réel, exprimée en points de pourcentage (où 5 est égal à 5 %). Pour le S&P 500, toutes les observations ont été conservées, aucune valeur aberrante n’a été supprimée.
Prévoir ou se souvenir ?
Cela semble impressionnant – et ça l’est – mais cela nous met sur la mauvaise voie. Lorsque nous demandons aux modèles de langage de faire des prédictions sur des dates antérieures à leur cut-off (par exemple octobre 2023 pour GPT-4o), la question est de savoir si le modèle fait réellement des prédictions ou s’il se contente de ressortir ce qu’il a déjà vu.
Les chercheurs donnent un exemple : supposons que vous demandiez à ChatGPT de prédire l’évolution du PIB américain au quatrième trimestre 2008, et que vous ne fournissiez des données que jusqu’au troisième trimestre 2008. Vous attendez une évaluation, une analyse, un peu de flair économique. Qu’est-ce que vous obtenez ? Une analyse apparemment brillante… qui se révèle également tout à fait juste. Pourquoi ? Parce que le modèle connaissait déjà les données du quatrième trimestre 2008. Il fait semblant de prédire, mais en réalité il connaît déjà la réponse. C’est comme si l’on demandait à un élève de remplir un test qu’il a vu la veille sans faire exprès.
Même lorsque vous demandez explicitement au modèle de ne pas utiliser de données postérieures à une certaine date, il s’obstine à donner des réponses correctes. C’est comme si on demandait à quelqu’un « d’oublier ce qu’il sait sur la crise financière » – bonne chance.
Même lorsque les chercheurs masquent les données (en remplaçant les noms par « Entreprise X », en omettant les années, en masquant des chiffres spécifiques), le modèle est souvent toujours capable de deviner quelle entreprise est impliquée et dans quel trimestre le rapport a été rédigé. C’est parce qu’il reconnaît les schémas même lorsque les détails sont absents. ChatGPT sait donc que « l’Entreprise X » est en fait Meta, et qu’il s’agit du 1er trimestre 2018.
Qu’est-ce que cela signifie pour vous en tant qu’investisseur ? C’est simple : si vous utilisez des LLM pour entraîner des modèles, tester des scénarios historiques ou backtester des stratégies hypothétiques, vous pouvez facilement vous faire avoir. Vous pensez que le modèle a déduit quelque chose d’intelligent, mais en fait il ne fait que répéter ce qu’il a déjà vu. La prédiction est différente de la mémorisation. Une solution évidente consiste à ne travailler qu’avec des données postérieures au knowledge cut-off du modèle.
Cela rappelle un peu le célèbre Jugement de Paris de 1976, où les vins américains avaient obtenu contre toute attente des notes supérieures aux classiques français. Tout le monde pensait que les États-Unis avaient gagné. Ensuite, on y regarde de plus près : était-ce une coïncidence ? Était-ce le contexte ? Ou simplement une année particulièrement bonne ? Si nous demandons à ChatGPT qui gagne en 1976, il vous citera sans aucun doute les bons vins, les bonnes notes et les bons juges. Mais la question se pose : s’il vous donne une prédiction pour 1975, s’agit-il d’une analyse ou d’un simple travail de mémoire ?
Gertjan Verdickt est professeur assistant de finance à l’université d’Auckland et chroniqueur pour Investment Officer.