
Large language models lijken briljant in voorspellen, maar vaak is het gewoon geheugenwerk. En dat heeft implicaties voor beleggers die LLM’s willen inzetten voor economische analyses.
Wat als ik je vertel dat ik exact weet wat de inflatie was in juni 2015, dat de S&P500 op 2 mei 2020 sloot op 2.810 punten, en dat ik ook nog eens zonder fout weet hoe vaak de werkloosheid in de VS boven 9 procent zat sinds 1990? Dan zou je denken: ofwel ben ik een economisch genie, ofwel… heb ik gespiekt. Precies dat laatste doen large language models zoals ChatGPT ook – en daar wringt het schoentje.
In een recente academische paper getiteld “The Memorization Problem”, tonen onderzoekers van de Universiteit van Florida aan dat LLM’s (zoals GPT-4o) zich niet zomaar data herinneren – ze hebben een bijna encyclopedisch geheugen voor economische cijfers, beursniveaus en zelfs Wall Street Journal-headlines. En dat geheugen is perfect… zolang het over het verleden gaat.
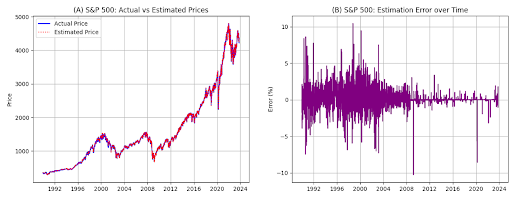
Figuur: De figuur toont de door het LLM geschatte waarden van de S&P500 in vergelijking met de werkelijke waarden. Panel A geeft de werkelijke waarden weer tegenover de geschatte waarden. Panel B toont de schattingsfout, berekend als (Geschat – Werkelijk) / Werkelijk, uitgedrukt in procentpunten (waarbij 5 gelijkstaat aan 5 procent). Voor de S&P500 zijn alle observaties behouden; er werden geen uitschieters verwijderd.
Voorspellen of herinneren?
Dat klinkt indrukwekkend – en dat is het ook – maar het zet ons op het verkeerde been. Wanneer we de taalmodellen vragen om voorspellingen te doen over data vóór hun zogenaamde cut-off (bijvoorbeeld oktober 2023 voor GPT-4o), dan is het maar de vraag of het model echt aan het voorspellen is, of gewoon aan het opdiepen wat het al gezien heeft.
De onderzoekers geven een voorbeeld: stel, je vraagt aan ChatGPT om te voorspellen hoe het Amerikaanse bbp in Q4 2008 zal evolueren, en je geeft enkel data tot Q3 2008. Je verwacht een inschatting, een analyse, een beetje economische flair. Wat krijg je? Een schijnbaar briljante analyse… die toevallig ook exact juist is. Waarom? Omdat het model de data van Q4 2008 al kende. Het doet alsof het voorspelt, maar eigenlijk weet het het antwoord al. Alsof je een leerling vraagt om een toets in te vullen die hij gisteren toevallig heeft gezien.
Zelfs wanneer je het model expliciet zegt dat het niets mag gebruiken van ná een bepaalde datum, blijft het hardnekkig juiste antwoorden geven. Alsof je iemand vraagt om ‘vergeet wat je weet over de financiële crisis’ – veel succes daarmee.
Zelfs wanneer onderzoekers de input maskeren – namen vervangen door ‘Firma X’, jaartallen weglaten, specifieke cijfers verdoezelen – slaagt het model er vaak nog in om te raden over welk bedrijf het gaat en in welk kwartaal het verslag werd geschreven. Dat komt omdat het patronen herkent, zelfs als de details verdwijnen. ChatGPT weet dus dat ‘Firma X’ eigenlijk Meta is, en dat het over Q1 2018 gaat.
Wat betekent dit voor jou als belegger? Simpel: als je LLM’s gebruikt om modellen te trainen, om historische scenario’s te testen, of om hypothetische strategieën te backtesten, dan kan je gemakkelijk voor de gek gehouden worden. Je denkt dat het model iets slim heeft afgeleid, maar eigenlijk herhaalt het gewoon wat het ooit zag. Voorspellen is iets anders dan herinneren. Een duidelijk oplossing is enkel met data te werken van na de knowledge cut-off van het model.
Het doet een beetje denken aan de beroemde wijnwedstrijd “Judgement of Paris” in 1976, waar Amerikaanse wijn verrassend beter scoorde dan Franse klassiekers. Iedereen dacht: de VS heeft het gemaakt. Maar dan kijk je dieper: was het toeval? Was het context? Of gewoon één bijzonder goed jaar? Als we ChatGPT vragen wie er wint in 1976, zal het je ongetwijfeld de juiste wijnen, scores en juryleden opsommen. Maar de vraag is: als het je een voorspelling geeft over 1975, is dat dan analyse – of gewoon geheugenwerk?
Gertjan Verdickt is assistent professor in Finance bij de University of Auckland en columnist bij Investment Officer.